


“이번 달 BigQuery 청구서가 왜 이렇게 많이 나왔지?”
GA4 데이터를 BigQuery로 내보내고 열심히 분석하다 보면 어느 날 갑자기 예상치 못한 비용 청구서를 받게 되는 경우가 있습니다. 특히 데이터가 쌓이기 시작하면서 무심코 실행한 쿼리 하나가 수십 TiB의 데이터를 스캔해버리는 일이 생기기도 하죠.
이번 글에서는 BigQuery 비용이 어떻게 발생하는지 이해하고, 파티션과 클러스터링을 활용해 비용을 효과적으로 절감하는 방법을 알아보겠습니다.
목차
BigQuery 비용 구조 이해하기
BigQuery 비용을 줄이려면 먼저 비용이 어떻게 발생하는지 알아야 합니다. BigQuery의 비용은 크게 쿼리 비용과 스토리지 비용 두 가지로 나뉩니다.
쿼리 비용 (온디맨드 요금제 기준)
쿼리 비용은 쿼리가 스캔한 데이터 양에 따라 부과됩니다. 중요한 점은 쿼리 결과의 크기가 아니라 쿼리가 읽은 데이터의 총량이라는 것입니다.
| 항목 | 비용 |
|---|---|
| 쿼리 처리 비용 (미국 기준) | $6.25 / TiB |
| 쿼리 처리 비용 (서울 리전) | $7.50 / TiB |
| 월 무료 한도 | 1TiB |
예를 들어, 100GiB 테이블에서 SELECT * 쿼리를 실행하면 결과가 1행이든 100만 행이든 100GiB 전체를 스캔한 비용이 청구됩니다.
스토리지 비용
스토리지 비용은 저장된 데이터 양에 따라 매월 부과됩니다.
| 항목 | 비용 |
|---|---|
| 활성 논리 스토리지 | $0.023 / GiB / 월 |
| 장기 논리 스토리지 (90일 후) | 약 50% 할인 |
| 월 무료 한도 | 10GiB |
90일 동안 수정되지 않은 테이블은 자동으로 장기 스토리지로 분류되어 비용이 절반으로 줄어듭니다.
비용 계산 예시
실제로 어느 정도의 비용이 발생하는지 간단히 계산해 보겠습니다.
- 일일 저장 데이터: 약 5GiB
- 한 달 누적 데이터: 약 150GiB
- 매일 전체 테이블 스캔 쿼리 10회 실행 시
월간 쿼리 스캔량: 150GiB x 10회 x 30일 = 45TiB
월간 쿼리 비용: (45TiB - 1TiB 무료) x $7.50 = 약 $330무심코 실행한 쿼리가 쌓이면 상당한 비용이 될 수 있습니다. 하지만 파티션과 클러스터링을 잘 활용하면 이 비용을 90% 이상 줄일 수 있습니다.
파티션으로 비용 줄이기
파티션이란?
파티션은 하나의 큰 테이블을 특정 기준(주로 날짜)에 따라 여러 개의 작은 조각으로 나누는 것입니다. 쿼리 시 필요한 파티션만 스캔하므로 비용을 크게 절감할 수 있습니다.
GA4의 파티션 구조
GA4 데이터를 BigQuery로 내보내면 자동으로 날짜별 파티션 테이블이 생성됩니다. 테이블 이름이 events_YYYYMMDD 형식으로 되어 있는 것을 보셨을 것입니다.
analytics_123456789.events_20260101
analytics_123456789.events_20260102
analytics_123456789.events_20260103
...이 구조 덕분에 특정 날짜 범위의 데이터만 조회할 수 있습니다. 하지만 이를 제대로 활용하려면 쿼리에서 날짜 범위를 명시해야 합니다.
_TABLE_SUFFIX를 활용한 날짜 필터링
GA4 테이블에서 날짜 범위를 지정할 때는 _TABLE_SUFFIX를 사용합니다.
-- 좋은 예: 특정 기간만 스캔 (약 7일치 데이터만 읽음)
SELECT
event_name,
COUNT(*) AS event_count
FROM
`프로젝트ID.analytics_123456789.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20260101' AND '20260107'
GROUP BY
event_name-- 나쁜 예: 전체 테이블 스캔 (모든 데이터를 읽음)
SELECT
event_name,
COUNT(*) AS event_count
FROM
`프로젝트ID.analytics_123456789.events_*`
GROUP BY
event_name1년치 데이터가 쌓여 있다면, _TABLE_SUFFIX 조건 유무에 따라 스캔량이 365배 차이 날 수 있습니다.
파티션 필터 강제화하기
실수로 전체 테이블을 스캔하는 것을 방지하려면 require_partition_filter 옵션을 설정할 수 있습니다. 이 옵션이 설정된 테이블은 파티션 필터 없이 쿼리를 실행하면 오류가 발생합니다.
-- 테이블에 파티션 필터 필수 설정
ALTER TABLE `프로젝트ID.데이터세트ID.테이블명`
SET OPTIONS (require_partition_filter = true)단, GA4에서 자동으로 생성되는 테이블에는 이 설정을 직접 적용하기 어려우므로, GA4 데이터를 가공하여 별도 테이블로 저장할 때 이 옵션을 활용하는 것을 권장합니다.
클러스터링으로 더 최적화하기
클러스터링이란?
클러스터링은 파티션 내에서 데이터를 특정 컬럼 기준으로 정렬하여 저장하는 기능입니다. 자주 필터링하는 컬럼을 클러스터링 키로 지정하면 쿼리 성능이 향상되고 스캔량이 줄어듭니다.
클러스터링의 장점
| 파티션 | 클러스터링 |
|---|---|
| 테이블을 물리적으로 분리 | 파티션 내 데이터를 정렬 |
| 날짜 기반 필터에 효과적 | 다양한 컬럼 필터에 효과적 |
| 스캔 범위를 크게 줄임 | 추가적인 스캔 최적화 |
GA4 데이터에 적합한 클러스터링 컬럼
GA4 데이터를 분석할 때 자주 사용하는 필터 조건에 따라 클러스터링 컬럼을 선택합니다.
- event_name: 특정 이벤트만 분석할 때 유용
- user_pseudo_id: 특정 사용자의 행동을 추적할 때 유용
- device.category: 디바이스별 분석 시 유용
클러스터링은 최대 4개 컬럼까지 지정할 수 있습니다.
클러스터링 테이블 생성 예시
GA4 데이터를 가공하여 클러스터링이 적용된 테이블을 만들 수 있습니다.
-- 클러스터링이 적용된 테이블 생성
CREATE TABLE `프로젝트ID.데이터세트ID.events_clustered`
PARTITION BY event_date
CLUSTER BY event_name, user_pseudo_id
AS
SELECT
PARSE_DATE('%Y%m%d', event_date) AS event_date,
event_name,
user_pseudo_id,
event_timestamp,
-- 필요한 컬럼들 추가
FROM
`프로젝트ID.analytics_123456789.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20260101' AND '20260121'이렇게 만든 테이블에서 특정 이벤트를 조회하면 클러스터링 덕분에 해당 이벤트 데이터만 효율적으로 스캔합니다.
쿼리 최적화 실전 팁
파티션과 클러스터링 외에도 쿼리 작성 방식을 개선하면 비용을 더 줄일 수 있습니다.
1. SELECT * 대신 필요한 컬럼만 선택
BigQuery는 컬럼 기반 스토리지를 사용합니다. 필요한 컬럼만 선택하면 스캔량이 크게 줄어듭니다.
-- 나쁜 예: 모든 컬럼 스캔
SELECT *
FROM `프로젝트ID.analytics_123456789.events_*`
WHERE _TABLE_SUFFIX = '20260121'
-- 좋은 예: 필요한 컬럼만 스캔
SELECT
event_name,
event_timestamp,
user_pseudo_id
FROM `프로젝트ID.analytics_123456789.events_*`
WHERE _TABLE_SUFFIX = '20260121'2. LIMIT은 비용을 줄이지 않는다
많은 분들이 오해하는 부분입니다. LIMIT 절은 결과 행 수만 제한할 뿐, 스캔량은 줄이지 않습니다.
-- 이 쿼리도 전체 테이블을 스캔합니다
SELECT *
FROM `프로젝트ID.analytics_123456789.events_*`
LIMIT 10비용을 줄이려면 LIMIT 대신 WHERE 조건으로 데이터를 필터링해야 합니다.
3. UNNEST 사용 최소화
GA4 데이터에서 event_params를 조회할 때 UNNEST를 사용합니다. 하지만 UNNEST를 여러 번 사용하면 쿼리가 복잡해지고 비용이 증가할 수 있습니다.
-- 비효율적인 예: UNNEST 여러 번 사용
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_location,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS session_id
FROM `프로젝트ID.analytics_123456789.events_*`
WHERE _TABLE_SUFFIX = '20260121'
-- 더 효율적인 예: 서브쿼리로 한 번에 처리
SELECT
event_name,
MAX(IF(param.key = 'page_location', param.value.string_value, NULL)) AS page_location,
MAX(IF(param.key = 'page_title', param.value.string_value, NULL)) AS page_title,
MAX(IF(param.key = 'ga_session_id', param.value.int_value, NULL)) AS session_id
FROM `프로젝트ID.analytics_123456789.events_*`,
UNNEST(event_params) AS param
WHERE _TABLE_SUFFIX = '20260121'
GROUP BY event_name4. 쿼리 실행 전 예상 비용 확인
쿼리를 실행하기 전에 BigQuery 콘솔 우측 상단에서 예상 스캔량을 확인할 수 있습니다. 쿼리 유효성 검사 결과로 “실행 시 이 쿼리가 XXX GB를 처리합니다.”라는 메시지를 볼 수 있습니다.
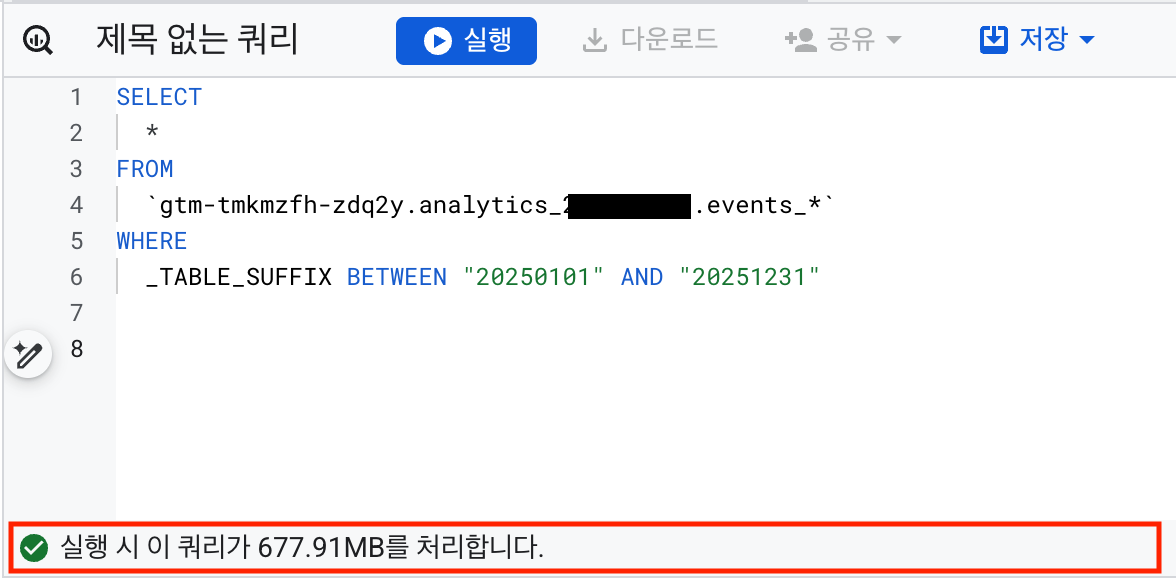
예상 스캔량이 너무 크다면 쿼리를 수정하여 비용을 줄이세요.
5. 중간 결과 테이블 활용
같은 데이터를 반복해서 분석한다면, 필요한 데이터만 추출하여 별도 테이블로 저장해두면 좋습니다.
-- 자주 사용하는 데이터를 별도 테이블로 저장
CREATE OR REPLACE TABLE `프로젝트ID.데이터세트ID.daily_sessions` AS
SELECT
PARSE_DATE('%Y%m%d', event_date) AS date,
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS session_id,
session_traffic_source_last_click.manual_campaign.source AS source,
session_traffic_source_last_click.manual_campaign.medium AS medium
FROM `프로젝트ID.analytics_123456789.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20260101' AND '20260121'
AND event_name = 'session_start'이후 분석에서는 원본 테이블 대신 이 요약 테이블을 사용하면 됩니다.
흔한 실수와 해결법
실수 1: SELECT * 남발
문제: 습관적으로 SELECT *를 사용하면 모든 컬럼을 스캔하게 됩니다.
해결: 필요한 컬럼만 명시적으로 선택하세요. 컬럼 구조를 파악할 때만 SELECT *를 사용하고, 그때도 LIMIT과 함께 사용하세요. (비용은 줄지 않지만 결과 확인용으로 유용합니다)
실수 2: LIMIT으로 비용 절감 시도
문제: LIMIT 100을 추가하면 100행만 스캔한다고 오해합니다.
해결: WHERE 조건으로 데이터를 필터링하세요. 특히 _TABLE_SUFFIX로 날짜 범위를 지정하는 것이 가장 효과적입니다.
실수 3: _TABLE_SUFFIX 조건 누락
문제: GA4 테이블 조회 시 날짜 조건을 빠뜨려 전체 기간 데이터를 스캔합니다.
해결: GA4 테이블 조회 시 항상 _TABLE_SUFFIX 조건을 포함하세요.
-- 필수! 항상 날짜 범위를 지정하세요
WHERE _TABLE_SUFFIX BETWEEN '시작일' AND '종료일'실수 4: 불필요한 UNNEST 중첩
문제: event_params의 여러 값을 가져올 때 서브쿼리마다 UNNEST를 반복 사용합니다.
해결: 가능하면 한 번의 UNNEST로 여러 파라미터를 추출하거나, 자주 사용하는 파라미터는 별도 테이블로 저장해두세요.
비용 모니터링하기
비용 최적화 못지않게 중요한 것이 지속적인 모니터링입니다. BigQuery의 INFORMATION_SCHEMA.JOBS 뷰를 활용하면 누가, 언제, 얼마나 많은 데이터를 스캔했는지 확인할 수 있습니다.
자세한 모니터링 방법은 아래 글을 참고해 주세요.
마무리
BigQuery 비용 최적화의 핵심을 정리하면 다음과 같습니다.
- 파티션 활용: GA4 테이블 조회 시 항상
_TABLE_SUFFIX로 날짜 범위 지정 - 클러스터링 적용: 자주 필터링하는 컬럼(event_name, user_pseudo_id)으로 클러스터링
- 필요한 컬럼만 선택: SELECT * 대신 필요한 컬럼만 명시
- LIMIT 오해 금지: LIMIT은 비용을 줄이지 않음
- 중간 테이블 활용: 반복 사용하는 데이터는 별도 테이블로 저장
이러한 방법들을 적용하면 BigQuery 비용을 50~90%까지 절감할 수 있습니다. 데이터 분석의 가치를 유지하면서도 효율적으로 비용을 관리해 보세요.
BigQuery 활용에 대해 더 알고 싶다면 아래 글들도 참고해 주세요.

